Yahya M. Mirza
Passionate QA Engineer specializing in manual, automation, and AI testing. Experienced in Playwright, Cypress, Selenium, Jest, CI/CD pipelines, and LLM evaluation frameworks to ensure software quality, reliability, and response accuracy.
What I do
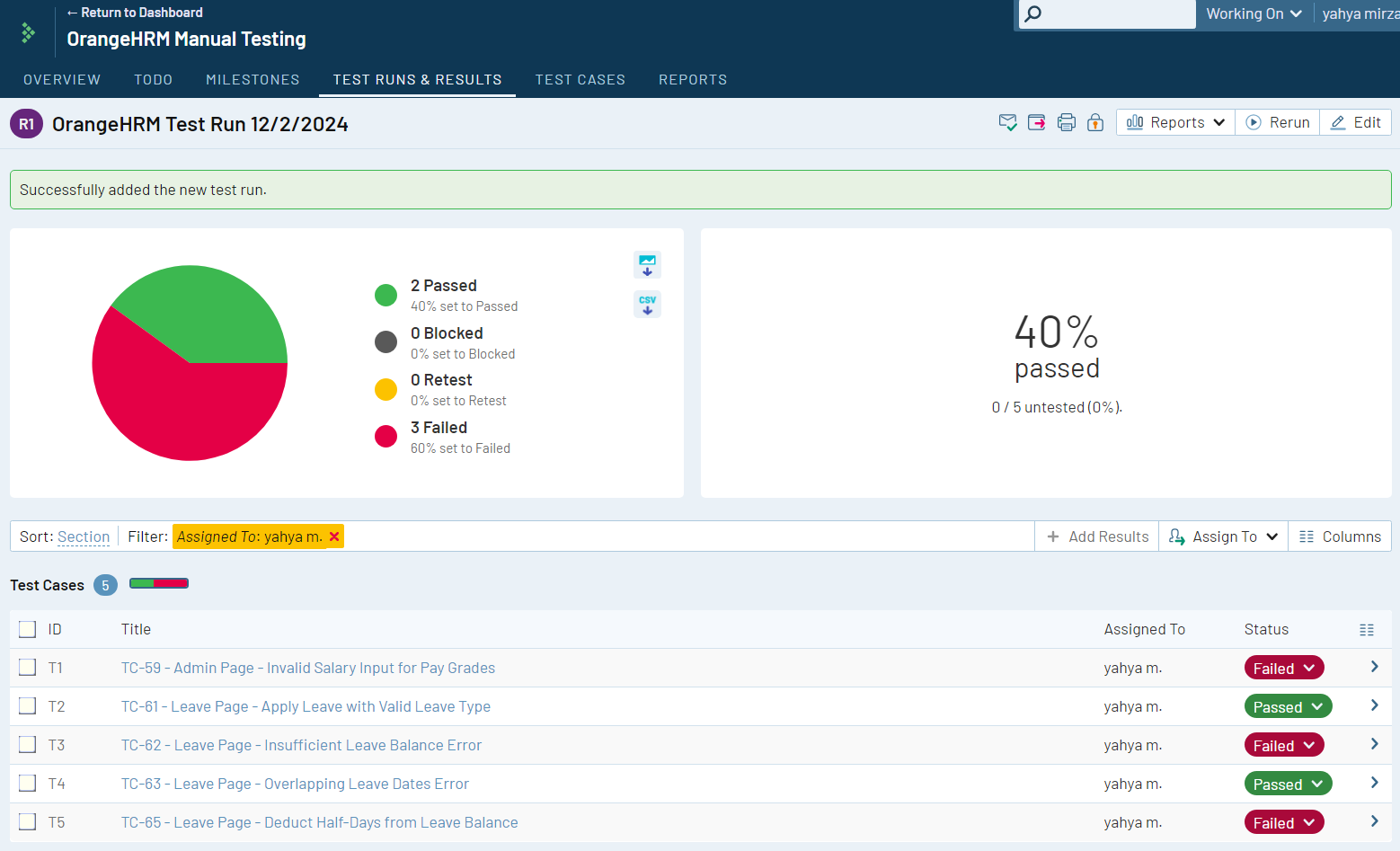

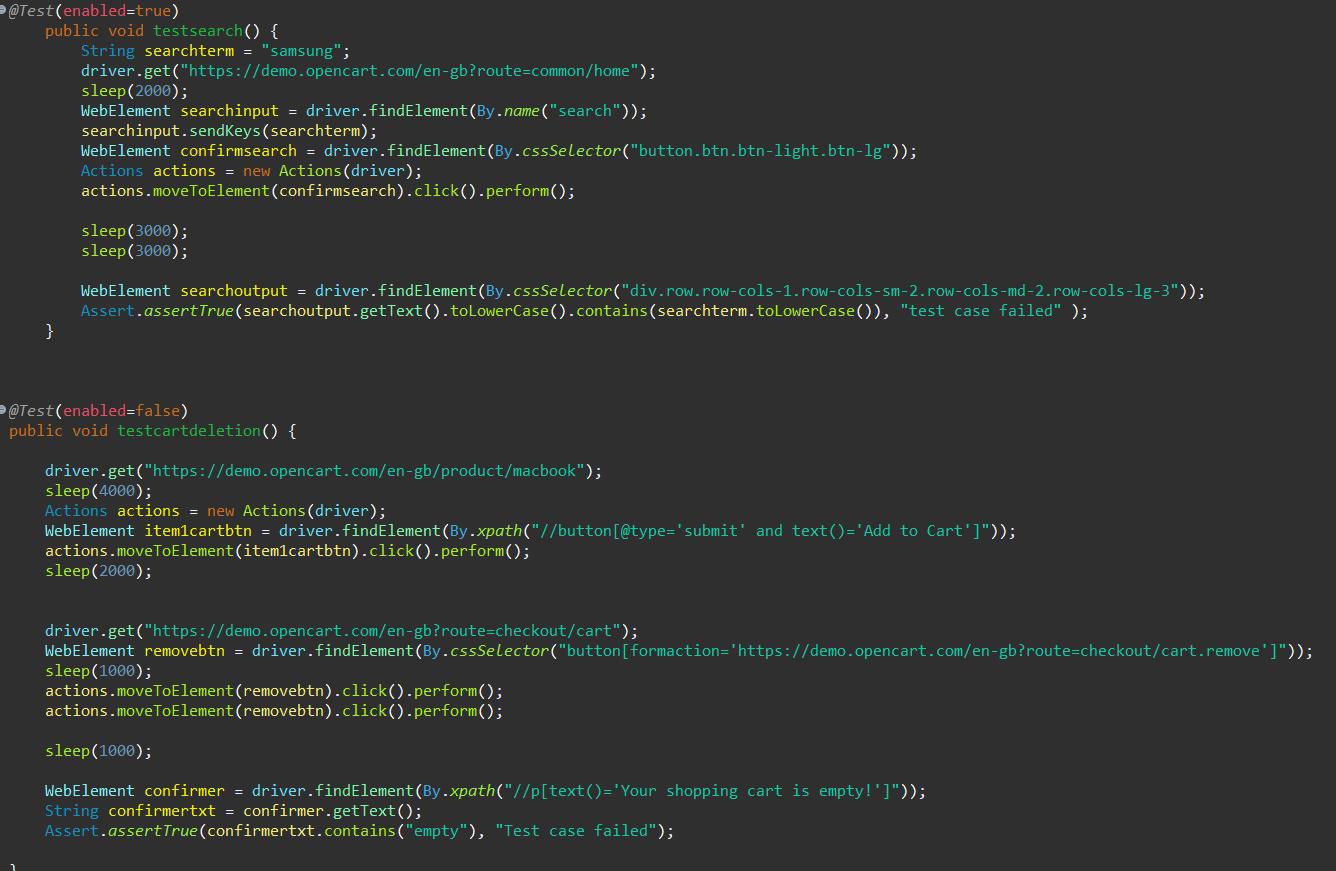
.png)